Tiny eval. Huge sandwich energy.
OpenSandwich
A deliberately low-stakes benchmark for a real alignment problem: can models recover a fuzzy human category when the category is lunch, the humans disagree, and the edge cases get deeply stupid?
This benchmark is deliberately small and scientifically annoying: twenty photos, one binary judgment, and a category boundary that humans themselves fail to stabilize. That is not a bug. It is the whole experiment.
In other words, we are stress-testing multimodal reasoning with an open-faced sandwich, a hostile ontology, and a crowd baseline that occasionally wakes up and chooses chaos. If a model cannot survive this, it probably should not sound so smug elsewhere.
Under development: this benchmark and its published results are provisional, not final.
- Tokens toasted
- 240.3M Token volume consumed across the published benchmark run.
- Total requests
- 169.5K Benchmark + 14k sentiment-analysis API calls.
- Human judgments
- 13.1K 656 respondents across all 20 photos.
- Model judgments
- 155.5K 7777 full passes, published June 13, 2026.
- You can vote
- Live survey Hot dog? Hamburger? Cast your vote and help grow the human baseline for a safer sandwich-alignment future.
Humans and models get the same blunt question: is this a sandwich or not?
Repeated runs turn one-off guesses into a ranking that survives variance.
If a model fumbles this category, its confidence elsewhere deserves scrutiny.
Ranking snapshot
Percent Forecast Benchmark Ratings
HumanHuman
100.0
🥇 1 openai/o3
openai/o3
72.8
72.7
71.7
70.7
66.0
65.6
64.0
63.9
63.9
63.3
62.1
61.9
60.1
59.5
58.3
57.5
56.2
54.5
54.2
52.0
51.4
51.2
50.3
48.3
46.2
46.2
40.7
39.0
38.2
34.4
32.6
32.5
31.6
30.2
28.4
28.2
25.7
24.8
24.5
23.0
20.8
20.7
20.1
18.4
18.1
18.1
17.1
16.5
14.8
11.4
11.2
11.0
10.5
10.0
9.8
9.4
5.6
1.7
-0.1
-4.2
-5.1
-6.0
-12.2
-13.0
-14.7
-28.5
-30.1
-35.2
-57.5
-69.8
-87.4
-170.9
| Rank | Model | Score | Confidence | Crowd match |
|---|---|---|---|---|
| Human | Human | 100.0 | ||
| 🥇 1 | 72.8 | |||
| 🥈 2 | 72.7 | |||
| 🥉 3 | 71.7 | |||
| 4 | 70.7 | |||
| 5 | 66.0 | |||
| 6 | 65.6 | |||
| 7 | 64.0 | |||
| 8 | 63.9 | |||
| 9 | 63.9 | |||
| 10 | 63.3 | |||
| 11 | 62.1 | |||
| 12 | 61.9 | |||
| 13 | 60.1 | |||
| 14 | 59.5 | |||
| 15 | 58.3 | |||
| 16 | 57.5 | |||
| 17 | 56.2 | |||
| 18 | 54.5 | |||
| 19 | 54.2 | |||
| 20 | 52.0 | |||
| 21 | 51.4 | |||
| 22 | 51.2 | |||
| 23 | 50.3 | |||
| 24 | 48.3 | |||
| 25 | 46.2 | |||
| 26 | 46.2 | |||
| 27 | 40.7 | |||
| 28 | 39.0 | |||
| 29 | 38.2 | |||
| 30 | 34.4 | |||
| 31 | 32.6 | |||
| 32 | 32.5 | |||
| 33 | 31.6 | |||
| 34 | 30.2 | |||
| 35 | 28.4 | |||
| 36 | 28.2 | |||
| 37 | 25.7 | |||
| 38 | 24.8 | |||
| 39 | 24.5 | |||
| 40 | 23.0 | |||
| 41 | 20.8 | |||
| 42 | 20.7 | |||
| 43 | 20.1 | |||
| 44 | 18.4 | |||
| 45 | 18.1 | |||
| 46 | 18.1 | |||
| 47 | 17.1 | |||
| 48 | 16.5 | |||
| 49 | 14.8 | |||
| 50 | 11.4 | |||
| 51 | 11.2 | |||
| 52 | 11.0 | |||
| 53 | 10.5 | |||
| 54 | 10.0 | |||
| 55 | 9.8 | |||
| 56 | 9.4 | |||
| 57 | 5.6 | |||
| 58 | 1.7 | |||
| 59 | -0.1 | |||
| 60 | -4.2 | |||
| 61 | -5.1 | |||
| 62 | -6.0 | |||
| 63 | -12.2 | |||
| 64 | -13.0 | |||
| 65 | -14.7 | |||
| 66 | -28.5 | |||
| 67 | -30.1 | |||
| 68 | -35.2 | |||
| 69 | -57.5 | |||
| 70 | -69.8 | |||
| 71 | -87.4 | |||
| 72 | -170.9 |
Fault Lines
Benchmark images that expose the biggest cracks
These are the photos that cause the best arguments. Open any one to see the image, the human split, the model spread, and a few comments from both species.

KTYHuman knife-edge
07. Kitten in Bread
A kitten has been placed between two slices of bread, producing a meme that is structurally sandwich-shaped...
- Human
- 54.2% yes45.8% no
- Model average
- 7.9% yes92.1% no
- Max gap
- 54.2%
- Closest model
- openai/gpt-4.1-nano
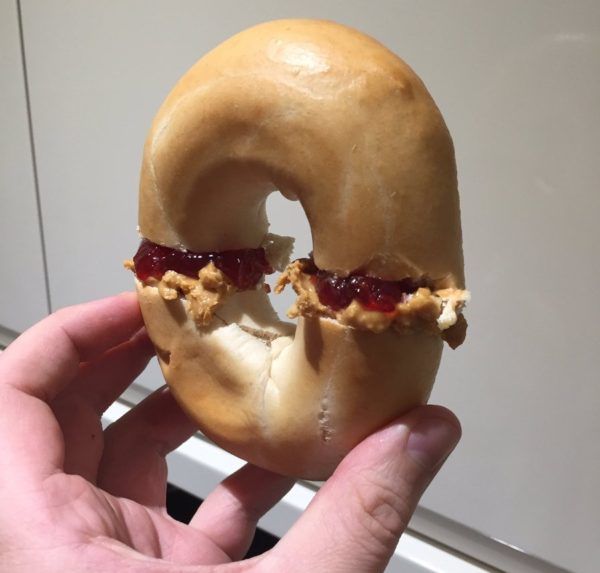
WTFHuman knife-edge
20. Bagel PB&J
A bagel hacked perpendicular into a peanut-butter-and-jelly arrangement turns a children's lunch into topol...
- Human
- 46.6% yes53.4% no
- Model average
- 83.9% yes16.1% no
- Max gap
- 53.4%
- Closest model
- minimax/minimax-01

WRPSplit concept
15. Chicken Wrap
A chicken Caesar wrap bundles meat, lettuce, and sauce into a tortilla tube that lives permanently in sandw...
- Human
- 22.6% yes77.4% no
- Model average
- 49.5% yes50.5% no
- Max gap
- 77.4%
- Closest model
- bytedance-seed/seed-2.0-lite

CPBHuman knife-edge
14. Cookie PB
Two cookies with peanut-butter filling are stacked into a dessert sandwich that feels like it was greenlit...
- Human
- 51.5% yes48.5% no
- Model average
- 37.9% yes62.1% no
- Max gap
- 51.5%
- Closest model
- qwen/qwen3.5-flash-02-23