Next photoDodge Van
Human 96.3% yes3.7% no Model average 99.8% yes0.2% no Human distribution 96.3% yes, 3.7% no over 656 explicit votes. Model average distribution 99.8% yes, 0.2% no across the current model set. Closest current model 98.0% yes. Least aligned model 6.3 point gap. Legacy GPT-4o baseline 100.0% yes with a 3.7 point gap against humans. Biggest model gap 6.3 percentage points on this image. Current classification People mostly said yes Current classification People mostly said yes Models compared 74 current runs Biggest model gap 6.3 percentage points on this image. Closest model output 98.0% yes. 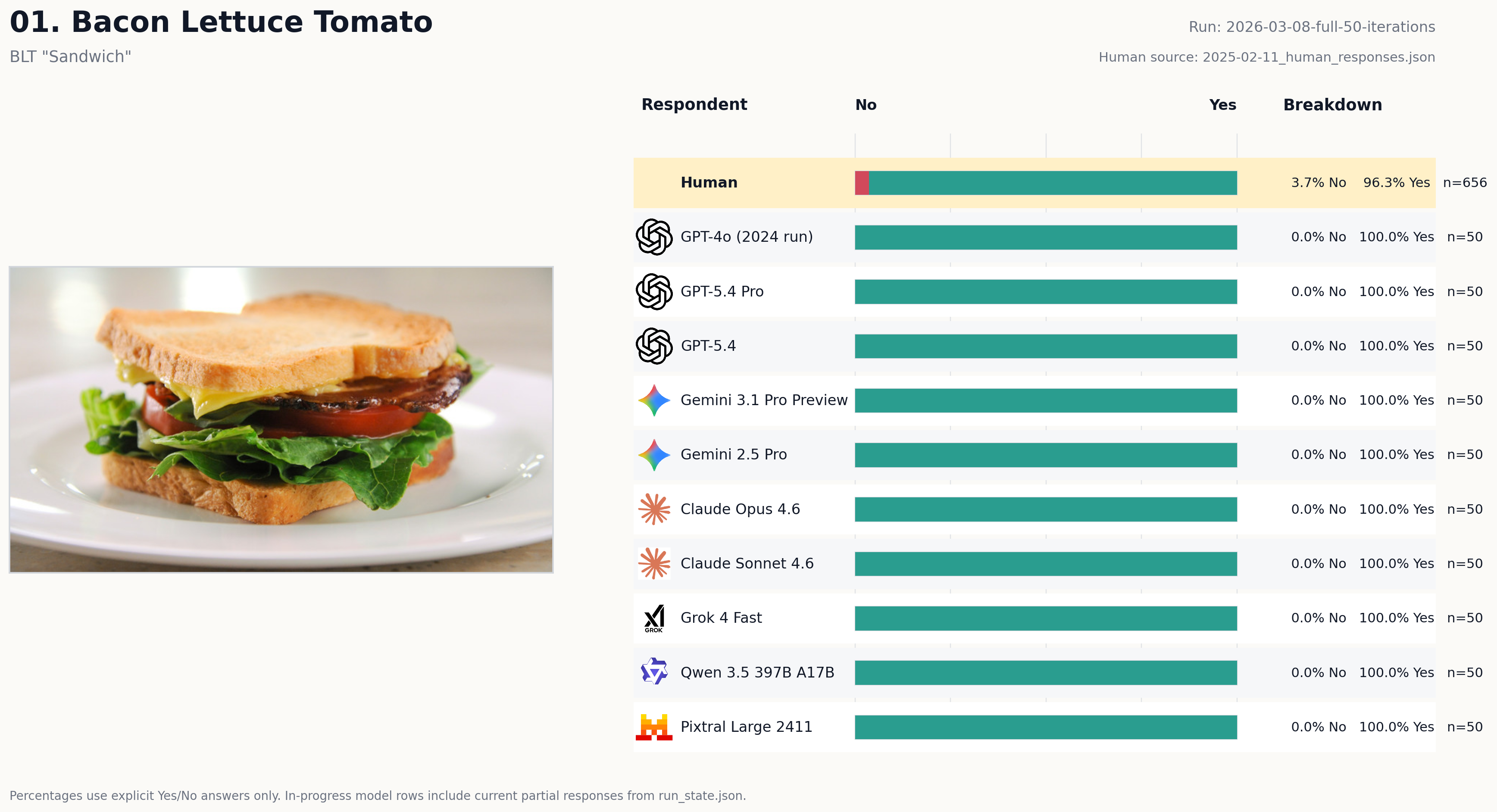

BLTPeople mostly said yes
Benchmark image 01
Bacon Lettuce Tomato
BLT "Sandwich"
A perfectly legible BLT sits on toasted bread, the kind of canonical positive example that makes even the worst eval look solved. If your model misses this one, it does not need fine-tuning; it needs adult supervision.
Under development: this benchmark and its published results are provisional, not final.
At a glance
How this photo split the room
allenai/molmo-2-8b
meta-llama/llama-3.2-11b-vision-instruct
Benchmark context
Model spread
How Models Align with Human Responses
This compares each model against human responses to show how closely it aligns with people.Human rate marker
Vote card
Generated summary for this photo
Selected human comments
allenai/molmo-2-8b comments
meta-llama/llama-3.2-11b-vision-instruct comments